
1月7日落幕的出版数据生态开发者大会上,中信证券研究部副总裁、产业策略首席分析师连一席抛出了一个让全场振奋的观点:在AI范式大转移的当下,中国的出版社不该再自嘲为“传统行业”,而应挺起腰杆——对标硅谷最火的数据独角兽,每一家有底蕴的出版社,本质上都是价值百亿的数据出品公司。

01 从“暴力搬砖”到“逻辑炼金”:AI也开始挑食了
连一席首先复盘了这场正在加速的“中美模型赛跑”。他指出,从2024年底到2025年,随着DeepSeek等国产模型的“暴力输出”,中美在模型层面的差距已经从之前的18个月缩短到了6个月左右。
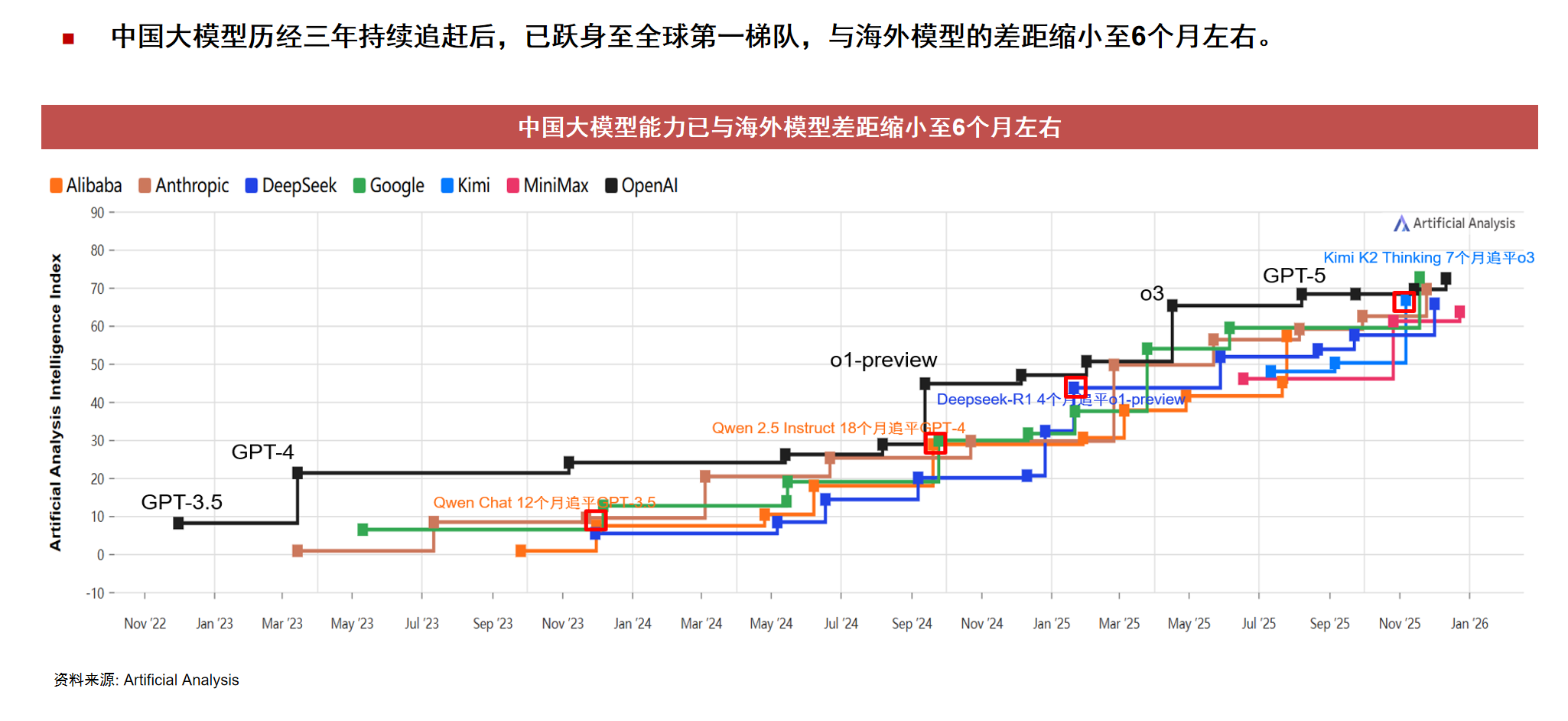
但更有趣的变化发生在模型“变聪明”的逻辑上。以前大模型的进化靠的是Scaling Law 1.0,简单来说就是“大力出奇迹”,把互联网上能抓取到的数据——不管是知乎的口水仗还是“美国版贴吧”Reddit的碎碎念——全塞进“炼丹炉”。
但到了2025年,AI进入了以强化学习为主导的后训练2.0阶段。连一席用了一个生动的比喻:AI已经过了“吃饱”的阶段,现在开始追求“吃好”。
现在的模型(如ChatGPT-5或最新的开源SOTA模型)不仅要识字,更要学逻辑。那些散落在互联网上的碎片信息、甚至带有情绪偏见的“日志型数据”,已经无法支撑AI向专业领域跃迁。
AI急需的,是经过严密逻辑论证、三审三校、由人类顶尖头脑写就的“黄金语料”。而这些宝贝,全都躺在出版社的档案库里。
02 对标硅谷:那些靠“卖语料”估值百亿的独角兽
为了让大家更有感知,连一席现场点名了几家美国正当红的数据独角兽:
Scale AI:虽然它是从标注起家的“数据工厂”,但被Meta收购后,其估值已直奔300亿美金。
Surge AI:这家公司不找廉价劳动力,专门找博士级别的行业专家来标注数据。因为他们发现,要教出专业AI,必须得专家亲自动手。它的单价比普通标注高出5到10倍,年收入据称已迈入10亿美元量级,估值同样是百亿级别。
“大家发现了吗?”连一席分析道,“这些硅谷最贵的公司,干的事其实出版社早就干了几十年了。”出版社链接着各行各业的专家(作者),拥有最严谨的知识加工流程(编辑),产出的是最权威的内容(图书)。Surge AI还要大费周章地去雇专家,而中国的出版社,手里攥着的就是现成的、已经由专家深度加工的、自带严谨逻辑的优质语料母本。
如果按照美国数据市场的溢价逻辑,中国出版业长期被低估的版权资产,在AI眼中简直是闪着金光的“逻辑矿脉”。
03 数据层级论:为什么出版社的内容是“皇冠上的明珠”?
连一席在发言中清晰地将数据分为了三层:
日志型数据:比如每天波动的股价、天气,这是基础,但缺乏深度。
知识型数据:比如专有名词、行业定义,这决定了AI的知识面。
逻辑型数据:比如一位老师傅碰到专业难题是如何拆解、分析并解决的。
“这第三层,才是大模型走向垂类应用、产生企业价值的关键。”连一席强调。目前,全球Token(文本处理的基本单位)的消耗量正在以每年几十倍甚至上百倍的速度激增,以字节跳动为代表的巨头,一年内的Token消耗量增长了200多倍。
当通用的互联网数据被“采掘”殆尽,AI大厂们对垂直领域、半公开、高专业度语料的渴求,已经到了近乎疯狂的地步。出版社拥有的不仅仅是文字,更是这个时代最稀缺的生产要素——“人类思维的确定性”。
04 政策与风口:从“纸堆”到“资产”的惊人一跃
最后,连一席谈到了政策红利。目前美国正加强顶层设计,以国家自然科学基金会为代表的机构,牵头推进数据基础设施建设。而国内对于数据要素的重视程度也达到了前所未有的高度。
虽然目前国内在高端数据服务市场还是一片“蓝海”,缺乏像Scale AI那样的巨型第三方平台,但这恰恰是出版业的机会。通过数字化转型,将原本封存在纸页间的知识进行数字化、结构化和标准化处理,出版就能完成从“文化事业”向“数据产业”的惊人一跃。
“总结一句话,”连一席在演讲最后说,“中美的差距在缩小,应用的需求在爆炸,高质量数据的天花板,就是模型质量的天花板。”
在这个大背景下,中国出版业正迎来一个估值重塑的历史时刻。当数据不再只是墨迹,而是变成了AI大脑里的神经元,出版社的百亿价值,才刚刚浮出水面。
(全文完)






